July 10, 2026
by Himanshu Chowdhary

How mobile apps detect VPN and proxy users, the techniques they use, and how developers can respond without degrading user experience.
July 8, 2026

Malicious bot traffic can bypass traditional defenses using techniques like IP rotation, CAPTCHA solving, and human-like behavior. Learn how advanced bot mitigation strategies, behavioral analytics, and continuous monitoring help organizations detect and stop sophisticated automated threats.
June 10, 2026
by IP Location

Web scraping in 2026 is more competitive than ever. Websites now use
advanced anti-bot systems, behavioral fingerprinting, AI-powered
detection, IP reputation databases, and sophisticated rate-limiting
mechanisms to identify and block automated traffic. At the same time,
data collection has become increasingly important for SEO monitoring,
competit...
June 1, 2026
by IP Location

Proxy rotation helps you scale, but it can also break your data. Many sites change content by country, state, or even city. If your IP switches between regions, your scraper collects mixed pages and incorrect prices.
April 25, 2026
by IP Location

Not every proxy problem is about getting a new IP. Sometimes it is the opposite: you need to hold one identity long enough to finish the job without slowing down or tripping anti-bot systems. That is where ISP proxies fit. They are static IPs registered to an internet service provider but served from datacenter hardware, so the address stays put and the conn...
April 22, 2026
by IP Location

Web anti-bot systems have become increasingly sophisticated, evaluating not only how traffic behaves but also where it comes from. Simply using the fastest datacenter proxies will often trigger blocks, while relying exclusively on slower residential IPs can be cost-prohibitive.
April 2, 2026
by Jordan Blake

Online access tools are no longer limited to developers and security teams working on niche infrastructure. Today, marketers, analysts, sellers, researchers, and private users often need a mobile proxy when a task depends on a more natural network source and stronger trust signals. This article explains how mobile proxies work, where they perform best, how t...
April 2, 2026
by Jordan Blake
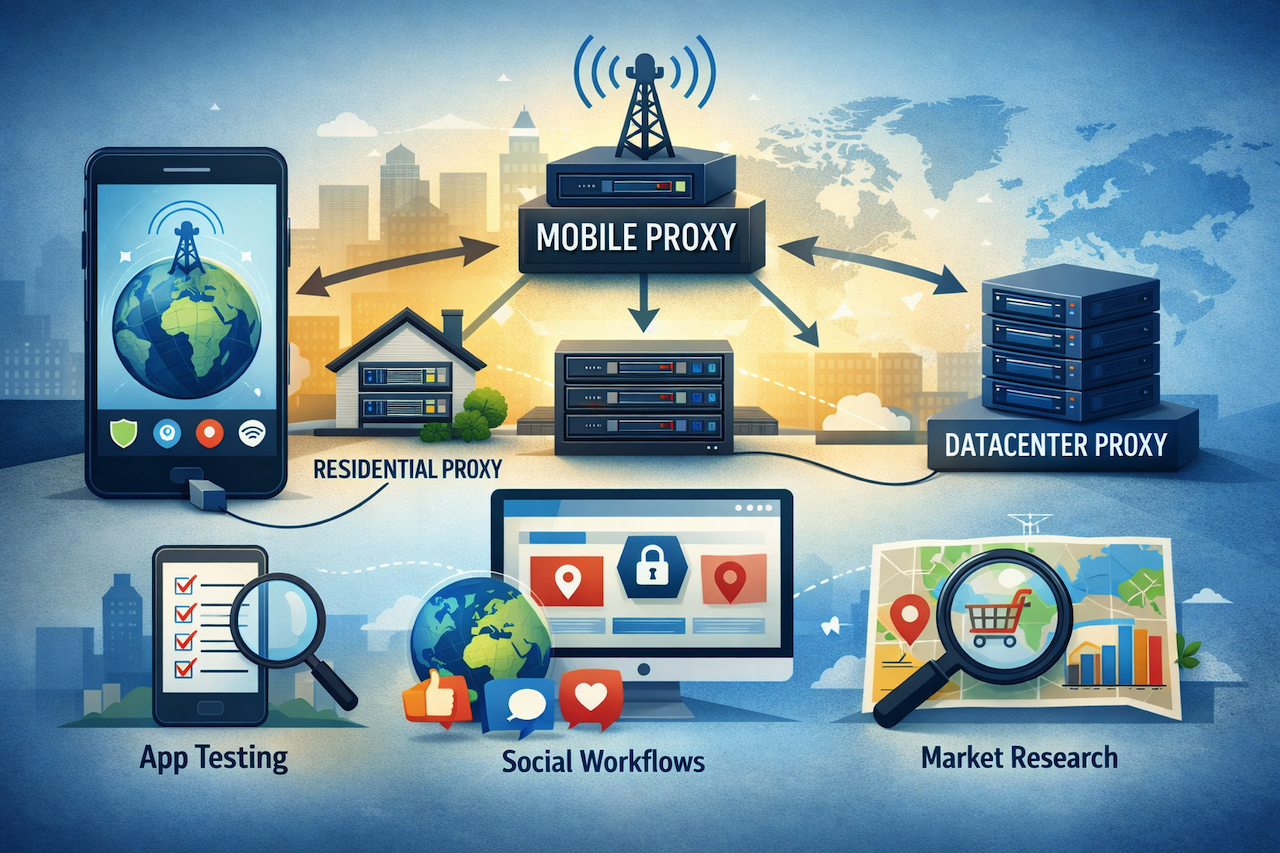
Modern online work often depends on access that looks natural, stays flexible, and adapts to changing locations or platforms. In that environment, a mobile proxy is often viewed as one of the most practical tools for users who need traffic routed through real mobile carrier networks instead of standard server infrastructure. This article explains how mobile...
April 1, 2026
by IP Location

Data scraping has evolved from a niche technical activity into a core business function. Companies rely on large-scale data collection for market intelligence, pricing analysis, SEO monitoring, and competitive research. However, as demand for data has increased, so has the sophistication of anti-bot protection systems.
March 30, 2026
by IP Location

When traffic leaves your usual connection and starts exiting through hosted infrastructure, IP geolocation stops reflecting your local access network and starts reflecting the network identity of the exit point. For readers who already know how IP lookups work at a high level, that shift is where the real story begins. A geolocation result is not a live GPS...