
It is a Tuesday afternoon. A revenue analyst at a mid-size online travel agency is refreshing a competitor's hotel listing for a beachfront resort in Cancun. She checks the price from her office laptop in New York: $189 per night. Curious, she asks a colleague in the London office to check the same hotel, same dates, same room type. He reports back: $214. She then pulls out her personal phone -- the one she used last week to search flights to Mexico -- and checks again. The price reads $231.
Same hotel. Same room. Same dates. Three different prices within a single hour.
This is not a glitch. It is travel pricing working exactly as designed. The modern travel industry runs on one of the most sophisticated dynamic pricing ecosystems ever built which factors in user history, device type, browsing behavior, geographic location, and dozens of other signals to serve each visitor a price that is calibrated specifically for them. For the traveler, this often means paying more than the baseline rate. For the data professional trying to collect accurate, comparable prices at scale, it means the data you are collecting may be fundamentally unreliable unless you know exactly what you are doing.
This guide is written for the engineers, analysts, and product teams who need to collect travel and hotel price data that is accurate, comprehensive, and trustworthy. It covers three essential pillars of reliable price collection: stripping personalization to obtain clean baseline prices, testing across multiple geographies to capture real market variation, and building the infrastructure to do both at scale. Woven throughout is a practical look at how residential proxies have become an indispensable tool for each of these challenges.
The Challenges of Collecting Travel and Hotel Price Data

Travel pricing is not merely dynamic but it is adversarial to data collection in ways that few other industries match. Understanding the specific challenges is the first step to building a system capable of overcoming them.

Dynamic Pricing at Machine Speed
Hotel prices on major OTAs can change hundreds of times per day. Algorithms factor in real-time demand signals, competitor pricing, days until check-in, cancellation policy flexibility, and even local event calendars. A price captured at 9 a.m. may be meaningfully different from the same property checked at 2 p.m. For price intelligence to be actionable, data freshness is not a nice-to-have, it is a core operational requirement.
Personalization and Price Discrimination
Travel platforms are among the most sophisticated practitioners of behavioral personalization. When you visit an OTA, the platform is already reading signals before you type a single character: your IP addressbrowser fingerprint reveals your device and operating system, your cookies carry your browsing and booking history, and your referral source hints at your intent and urgency. All of these signals feed pricing algorithms that may serve you a rate meaningfully different from what a first-time visitor would see.
Studies have found hotel price variations of up to 30% for the same room depending on user profile and requester location -- making de-personalization not just a technical preference, but a data integrity requirement.
Geo-Targeting and Currency Traps
A hotel in Paris listed at EUR 180 on the French version of a booking platform may appear as USD 210 on the US version -- not simply because of the exchange rate, but because of region-specific pricing strategies, local taxes displayed differently, and currency conversion margins embedded in the displayed price. Collecting prices from a single geographic vantage point produces a fundamentally incomplete picture of the market.
Anti-Bot Defenses
The world's largest OTAs invest heavily in bot detection and access control. IP reputation scoring, TLS fingerprinting, behavioral analysis, CAPTCHA challenges, and honeypot traps are all standard tools in their arsenal. Datacenter IP addresses, the traditional workhorse of web scraping, are often blocked outright or served degraded content. At scale, maintaining reliable access requires infrastructure that appears indistinguishable from genuine human browsing behavior.

Scale of Coverage
A comprehensive travel price dataset is not merely one hotel on one OTA. It spans thousands of properties across dozens of platforms, multiple room types, occupancy configurations, check-in windows ranging from same-day to six months out, and cancellation policy variations. The combinatorial scope is enormous, and building infrastructure that covers it reliably requires both architectural discipline and sustained operational maturity.
De-Personalized Pricing: Getting the Clean Price

What Price Personalization Actually Looks Like
Price personalization in travel is not a single mechanism but a layered system of signals and responses. At the most basic level, platforms read your IP address to infer your location, then serve region-appropriate pricing. More sophisticated systems read browser cookies to identify returning visitors, cross-reference device fingerprints against known high-intent user profiles, and adjust prices based on how many times you have viewed a particular property or searched a destination.
For data collection purposes, any of these signals can corrupt your dataset. If your collection infrastructure has visited a target OTA multiple times in recent sessions, the platform may begin serving loyalty-adjusted prices, urgency-inflated rates, or retargeting-influenced offers -- none of which represent the neutral baseline price required for competitive intelligence.
How Residential Proxies Enable True De-Personalization
This is where residential proxies become foundational rather than optional. A residential proxy routes your requests through IP addresses assigned to real residential internet connections: homes, apartments, and consumer devices in the target geography. From the perspective of the travel platform, the request appears to originate from an ordinary consumer browsing from their home network, carrying all the trust signals that genuine consumer traffic carries. In practice, many teams rely on providers such as Decodo Proxy to access large, high-quality residential IP pools that help maintain consistent, undetectable data collection across regions.
The key advantage for de-personalization is freshness at the identity level. A well-managed residential proxy pool allows you to assign a unique, clean residential IP to each collection session. That IP has no history with the target OTA, carries no cookies, triggers no behavioral profiling signals, and appears as a first-time visitor every time. Every session starts with a blank slate -- exactly the neutral baseline your competitive intelligence requires.
The Technical Stack for Clean Sessions
Achieving genuine de-personalization requires more than a residential IP. Each collection session should be configured with the following safeguards:
- Clean browser profile: A completely fresh profile with no cookies, local storage, or cached data from any prior session.
- Realistic user-agent: A randomized but plausible user-agent string matching the residential IP's apparent device and operating system profile.
- Fingerprint controls: Disabled or spoofed browser fingerprinting vectors, including canvas fingerprinting, WebGL fingerprinting, and font enumeration.
- Human-like timing: Request pacing and navigation patterns that mimic organic browsing behavior rather than machine-speed sequential requests.
- No IP-session reuse: Each new collection cycle should use a fresh residential identity -- never reusing an IP-session pairing from a prior run.
Validating That Your Prices Are Truly De-Personalized
The only reliable way to confirm that your de-personalization strategy is working is empirical validation. Run parallel collection sessions for the same target, one using your standard infrastructure and one using a fresh residential identity, and compare the prices returned. Consistent matches indicate clean baseline collection. Divergences reveal personalization leaks that need investigation. This cross-session price validation should be a standing component of any travel data quality framework.
Without active de-personalization validation, organizations may spend months building competitive intelligence on systematically biased data -- generating confident but incorrect conclusions about competitor pricing.
Multi-Country Testing: Capturing Geo-Specific Price Variations

Why Geography Is a First-Class Pricing Variable
The relationship between geography and travel pricing is both complex and commercially significant. It is not simply a matter of currency display. The underlying price itself often differs materially by market. A hotel chain running a promotional rate for the German market may not offer that same rate to visitors originating from the United States. An OTA may have negotiated different net rates with suppliers in different regions, resulting in genuinely different displayed prices for the same room on the same night.

Building Multi-Country Collection Infrastructure with Residential Proxies
Multi-country price testing requires collection infrastructure that can genuinely originate requests from within each target market, not just spoof a geographic header while actually connecting from a single location. This is the second major use case for residential proxies in travel price collection. A residential proxy pool with verified coverage across your target geographies allows you to route collection requests through IPs in each country, ensuring that the platform receives a request that passes all of its geographic validation checks.
The quality distinction matters enormously here. Datacenter proxies with falsified geolocation metadata are increasingly detected by sophisticated OTAs, which cross-reference IP geolocation against ASN data, connection characteristics, and behavioral signals. Genuine residential IPs in each target geography pass all of these checks because they are what they claim to be: real connections from real consumer networks in real locations.
Key markets for most travel price intelligence programs include the United States, United Kingdom, Germany, France, Japan, Australia, and the UAE. The right residential proxy provider maintains deep, genuine residential coverage across all of these markets -- not a handful of IPs per country, but pools large enough to sustain high-volume collection without exhausting the trust budget of individual addresses.
Normalizing Across Geographies
Raw multi-country price data requires careful normalization before it is meaningfully comparable. Key steps include applying consistent timestamped exchange rates, standardizing tax and fee treatment across markets, aligning rate plan classifications, and ensuring that all prices being compared were collected within the same narrow time window. Each of these steps requires both technical implementation and ongoing maintenance as platforms change their presentation conventions.
What Multi-Country Testing Reveals
When properly implemented, multi-country price testing surfaces commercially valuable insights that single-market collection cannot produce. It reveals which markets receive preferential rates for specific property categories, where OTAs apply currency conversion margins above the interbank rate, which regions are targeted with promotional pricing unavailable globally, and where tax presentation conventions create apparent but not real price differences. For competitive intelligence teams, this geo-pricing intelligence is often among the highest-value outputs of the entire price collection program.
Large-Volume Crawls: Building Comprehensive Price Coverage

Defining the True Scope of Comprehensive Travel Price Data
The scope of a genuinely comprehensive travel price dataset is larger than most organizations initially appreciate. Consider a single hotel property: it may be listed on 15 to 20 different OTAs and metasearch platforms, available in 5 to 10 different room types, with 3 to 5 rate plans per room type, across 180 check-in dates, and 7 different length-of-stay combinations. That is potentially tens of thousands of price points for a single property, before multi-country collection multiplies the scope further.

Architectural Principles for Scale
Production-grade travel price crawl infrastructure is distinguished from ad hoc scripts by a set of architectural choices that prioritize reliability, adaptability, and operational efficiency:
- Distributed execution: Crawl jobs parallelized across multiple agents, with work distributed by target domain, geography, and priority tier rather than processed sequentially from a single machine.
- Priority-based scheduling: High-value properties on tier-1 OTAs should be crawled more frequently than long-tail inventory. Scheduling must reflect commercial priorities, not just technical convenience.
- Adaptive rate management: Request pacing dynamically adjusted based on target responsiveness, error rates, and detected throttling signals. Fixed-rate crawlers that do not adapt will either underperform or trigger aggressive blocking responses.
- Graceful failure handling: At scale, some percentage of collection attempts will always fail. Retry logic, backoff strategies, and partial-crawl recovery mechanisms are essential for maintaining coverage SLAs.
The Role of Residential Proxies in Sustaining Large-Volume Crawls
At volume, the residential proxy layer is what separates collection infrastructure that sustains itself from infrastructure that collapses under blocking. Major travel OTAs maintain continuously updated block lists of known datacenter IP ranges. Requests from these addresses are either blocked outright or served deliberately degraded content designed to mislead automated collectors. Residential IPs, originating from genuine consumer devices, carry the trust signals that make high-volume collection sustainable.
For large-volume crawls, the key requirements of a residential proxy network are pool depth, geographic distribution, session control granularity, and rotation flexibility. A shallow pool that cycles through the same few hundred IPs will quickly exhaust the trust budget of those addresses against high-volume targets. Production-grade residential proxy networks provide access to millions of IPs across hundreds of geographies, with fine-grained control over session duration, rotation triggers, and geo-targeting parameters.
In comparative testing by independent travel data teams, residential proxy infrastructure has demonstrated success rates 3 to 5 times higher than datacenter proxy infrastructure against tier-1 OTA targets, with dramatically lower CAPTCHA encounter rates at equivalent request volumes.
Data Quality at Scale
Volume creates data quality challenges that manual review cannot address. Systematic automated quality monitoring is essential, covering range validation to flag implausible prices, cross-source reconciliation for properties listed on multiple platforms, completeness monitoring to track collection coverage per crawl cycle, and temporal consistency checks to surface structural page changes before they contaminate downstream analysis.
Integrating the Three Pillars into a Unified Data Pipeline
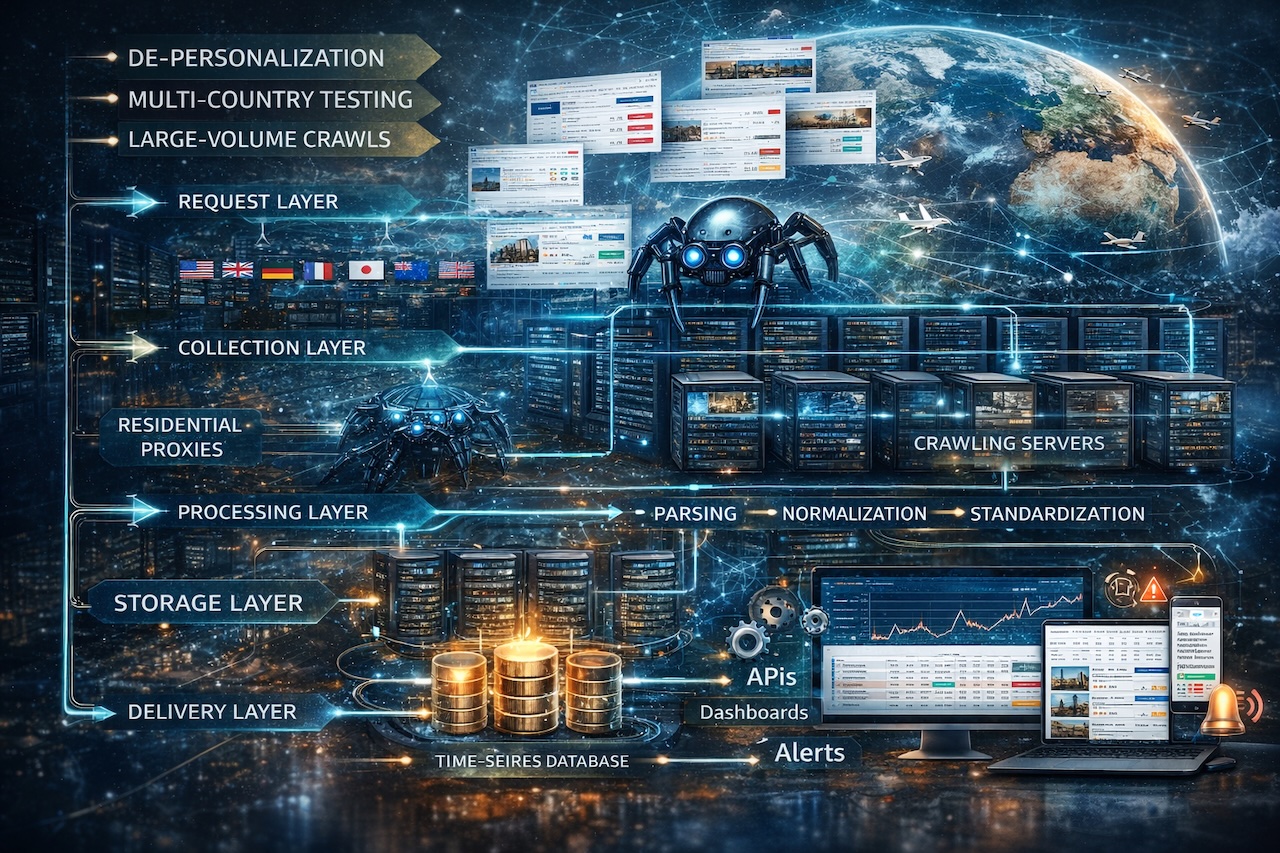
De-personalization, multi-country testing, and large-volume crawls are most powerful when they operate as an integrated system. The architecture of a production travel price data pipeline has five logical layers, each of which must be designed with the requirements of all three pillars in mind.
The request layer is where the three pillars converge at execution time. Each outbound request must be routed through the appropriate residential proxy endpoint for its target geography, initialized with a clean session identity, and paced according to the target domain's rate tolerance. Residential proxy selection at this layer must be dynamic: choosing IPs based on target geography, pool health, and recent blocking signals rather than simple round-robin rotation.
The collection layer manages crawl scheduling, execution, and retry logic. At this layer, the priority of each job, its geographic targeting, and its personalization requirements are translated into concrete execution parameters. Failures are caught, classified (transient network error, soft block, hard block, structural page change) and routed to the appropriate retry or escalation path.
The processing layer transforms raw HTML or API responses into structured price records. This includes parsing, currency normalization, tax treatment standardization, and rate plan classification. At scale, this layer must handle hundreds of different page structures reliably, with robust adaptation when target platforms change their layout without notice.
The storage layer must be optimized for the access patterns of travel price data: high write throughput during active crawl windows, efficient time-series queries for trend analysis, and fast point-in-time lookups for specific property-date-platform combinations. Purpose-built time-series databases significantly outperform general-purpose relational databases for this workload at scale.
The delivery layer exposes price data to downstream consumers through APIs, dashboards, and alerting mechanisms. For price intelligence applications, real-time alerting on significant price movements (a competitor dropping rates beyond a defined threshold, for example) is as important as historical trend access.
Data Quality, Compliance and Ethical Considerations
Building reliable travel price collection infrastructure is a technical challenge, but it is also a responsibility. Organizations that collect price data at scale must take seriously both the quality of what they collect and the manner in which they collect it.
Data accuracy requires periodic manual ground-truth validation, directly visiting target platforms through consumer browsers and comparing results to collected data. This reveals systematic collection errors that automated checks miss, such as incorrect parsing of fee structures or misclassification of rate plan types.
The legal landscape around automated price collection from travel platforms is nuanced and jurisdiction-specific. Organizations building price collection infrastructure should maintain awareness of applicable terms of service, computer access laws in their operating jurisdictions, and data protection requirements. From an ethical standpoint, collection infrastructure should be designed to minimize its footprint on target infrastructure, collect only what is necessary for the stated business purpose, and never facilitate consumer harm through price manipulation or deceptive data presentation.
Tools, Technologies and Infrastructure Recommendations

Proxy Infrastructure
For production travel price collection, residential proxies are the standard. Key selection criteria include pool size, verified geographic coverage across target markets, session control capabilities, rotation flexibility, and transparent IP sourcing practices. ISP proxies offer a useful middle ground for some use cases, providing higher stability than rotating residential IPs while carrying better trust signals than pure datacenter infrastructure.

Crawl Orchestration and Parsing
Purpose-built crawl orchestration frameworks that support distributed execution, priority scheduling, and adaptive rate management significantly outperform general-purpose task queues for large-volume travel collection. For parsing, production infrastructure must handle rendered HTML, embedded JSON, and JavaScript-rendered single-page applications with the ability to adapt quickly when target platforms change their structure.
Storage and Analytics
Time-series databases such as TimescaleDB or purpose-built columnar stores handle the access patterns of travel price data more efficiently than general-purpose relational databases. For organizations running analytics workloads on top of price data, a columnar analytics layer that supports fast aggregation across large price history datasets is worth the additional infrastructure investment.
Best Practices and Key Takeaways
- Always collect de-personalized prices: Personalized data does not just add noise and it introduces systematic bias that invalidates competitive analysis. No downstream processing can fix data collected with a corrupted identity.
- Treat multi-country testing as standard, not exceptional: Single-market collection produces a dangerously incomplete picture of competitive pricing. Build geo-testing into your standard collection cadence from day one.
- Invest in residential proxy infrastructure early: The cost difference between residential and datacenter proxies is modest compared to the reliability difference against tier-1 travel targets. Organizations that start with datacenter proxies and migrate to residential later consistently report wishing they had made the switch sooner.
- Make data freshness a first-class metric: In travel pricing, a price six hours old may already be wrong. Define freshness SLAs for each target tier and build monitoring that alerts when they are violated.
- Build for failure from day one: At scale, failures are not edge cases but they are routine. Retry logic, backfill strategies, and graceful degradation should be core architecture requirements, not afterthoughts.
- Document your collection methodology: Data consumers need to understand collection conditions to use data correctly. Clear documentation of your de-personalization approach, geographic coverage, and freshness guarantees builds trust in the dataset.
Conclusion
Back to our analyst from the opening. After implementing residential proxy-based de-personalized collection, multi-country geo-testing, and a high-volume crawl infrastructure, she no longer sees the $50 mystery as a confusing anomaly. She sees it for what it is: a documented, quantified, geo-specific pricing differential that her competitors are exploiting, and that her team can now factor into their own pricing strategy with precision.
That is the real value of reliable travel price collection. It is not just about having more data but it is about having data you can trust. Data that reflects the actual market rather than an artifact of how it was collected. In an industry where pricing algorithms operate at machine speed and personalization is the default, organizations that invest in building clean, comprehensive, geographically diverse price intelligence will carry a durable competitive advantage over those relying on incomplete or biased datasets.
The three pillars described in this guide: de-personalized pricing, multi-country testing, and large-volume crawls are not independent techniques but a unified methodology. Residential proxies are the connective tissue that makes all three work at production scale, providing the clean identities needed for de-personalization, the genuine geographic presence needed for geo-testing, and the trust signals needed to sustain high-volume collection without triggering blocking.
The starting point is an honest assessment of your current infrastructure against these standards. If you do not know whether your prices are de-personalized, they probably are not. If you are not testing across geographies, you are missing a significant dimension of the market. And if your crawl infrastructure was not built for scale, growth will eventually outpace its capacity. Each of these gaps is solvable and solving them will fundamentally change the quality of the competitive intelligence your organization can produce.
Images generated by ChatGPT.
Share this post
Leave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment