
In large-scale data operations, uninterrupted access to target sources is a core operational requirement. Whether you are running web-scraping pipelines, distributed monitoring systems, or automated data-collection workflows, the targets will block your access at some point. The frequency, sophistication, and consequences of blocking events have grown dramatically as websites and APIs have deployed increasingly advanced bot-detection and access-control mechanisms.
For organizations that rely on consistent, reliable access to external targets, downtime is not just an inconvenience but it translates directly into lost data, broken pipelines, violated SLAs, and wasted engineering hours. The old approach of addressing blocking events reactively simply does not scale. What was once a minor operational nuisance has become a discipline in its own right.
This article makes the case for a structural response to this challenge, built on two foundational pillars: dedicated unblocking teams and high-frequency monitoring. Together, these two elements form a resilient, scalable access infrastructure that keeps operations running smoothly even as blocking tactics evolve.
Understanding Target Blocking and Its Business Impact
Target blocking refers to any mechanism by which an external source restricts, limits, or denies access to your systems. This can take many forms: IP bans, geo-restrictions, rate limiting, CAPTCHA challenges, user-agent filtering, TLS fingerprinting, behavioral analysis, and more. In many cases, blocking is triggered not by any single action but by patterns of activity that deviate from expected human behavior.
The business impact of blocking events is significant and multi-dimensional. At the most immediate level, blocked access means data gaps — incomplete datasets, missed crawl cycles, and broken pipelines that downstream systems depend on. For organizations with contractual SLAs around data freshness or availability, even a short blocking event can trigger penalties or erode client trust. Beyond the direct operational impact, blocked access wastes engineering time as teams scramble to diagnose issues, implement workarounds, and restore access under pressure.
The nature of blocking itself has also evolved considerably. A decade ago, basic IP rotation was often sufficient to circumvent access restrictions. Today, sophisticated targets deploy multi-layered detection systems that analyze behavioral patterns, device fingerprints, request timing, and session characteristics simultaneously. Evading these systems requires a correspondingly sophisticated and coordinated response — one that goes far beyond simple infrastructure tricks.
Perhaps most importantly, the problem scales non-linearly. An organization managing ten target sources might be able to handle blocking events manually with reasonable effort. An organization managing thousands of targets across multiple geographies, crawl schedules, and data types cannot. At scale, the volume and variety of blocking events overwhelm any reactive, ad hoc response strategy.
The Case for a Dedicated Unblocking Team
1. Why Ad Hoc Responses Fall Short
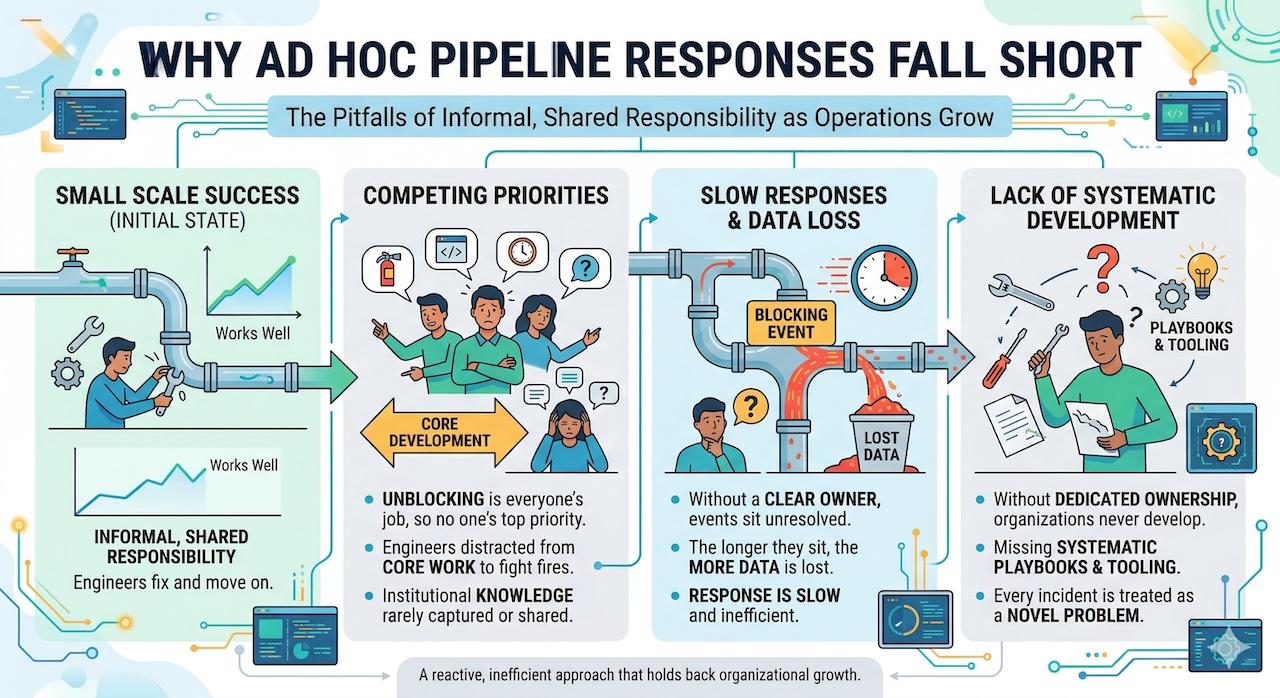
Many organizations begin their journey with blocking as an informal, shared responsibility. Engineers who notice a broken pipeline investigate the issue, implement a fix, and move on. This approach works reasonably well at small scale, but it has several critical failure modes as operations grow.
First, it creates competing priorities. When unblocking is everyone's job, it tends to become no one's top priority. Engineers are pulled away from core development work to fight fires, and the institutional knowledge gained from each incident is rarely captured or shared. Second, ad hoc responses are slow. Without a clear owner, blocking events sit unresolved until someone notices and the longer they sit, the more data is lost. Third, without dedicated ownership, organizations never develop the systematic playbooks and tooling needed to respond efficiently. Every incident is treated as a novel problem even when it isn't.
2. Core Responsibilities
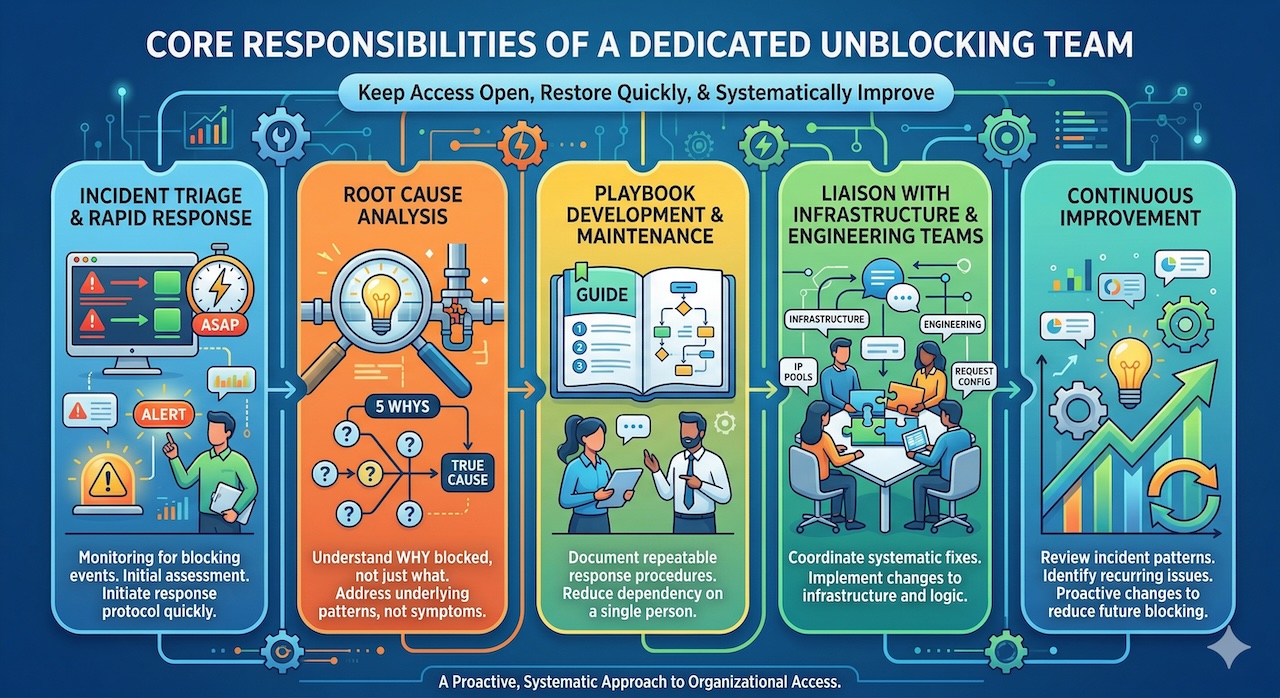
A dedicated unblocking team has a focused mandate: keep access open, restore it quickly when it is lost, and systematically improve the organization's ability to do both. The team's core responsibilities typically include:
- Incident triage and rapid response: Monitoring for blocking events and initiating the appropriate response protocol as quickly as possible.
- Root cause analysis: Determining not just what was blocked but why, so that the underlying pattern can be addressed rather than just the immediate symptom.
- Playbook development and maintenance: Documenting repeatable response procedures for common blocking scenarios so that resolution does not depend on any single person's knowledge.
- Liaison with infrastructure and engineering teams: Coordinating with the teams responsible for proxy infrastructure, IP pools, request configuration, and application logic to implement systematic fixes.
- Continuous improvement: Reviewing incident patterns, identifying recurring issues, and driving proactive changes to reduce blocking frequency and severity.
3. Team Structure and Skill Sets
The ideal composition of a dedicated unblocking team depends on the scale and complexity of the operation, but typically includes a blend of network engineers who understand proxy infrastructure and IP management, data engineers who can diagnose pipeline failures and trace data gaps to their source, automation specialists who can build and maintain the tooling needed for rapid response, and analysts who can identify patterns across large volumes of incidents. In practice, this often involves working closely with external proxy providers such as Decodo, which can supply high-quality IP pools and infrastructure support to help maintain consistent access across targets.
The team should have clear escalation protocols, defined ownership of different target categories, and the authority to make rapid decisions about infrastructure changes without lengthy approval cycles. Speed is often the most important factor in limiting the impact of a blocking event, and bureaucratic delays are the enemy of effective incident response.
4. Building Institutional Knowledge
One of the most valuable outputs of a dedicated unblocking team is the accumulation of institutional knowledge about how specific targets behave, what blocking patterns look like, and what interventions have been effective in the past. This knowledge should be systematically captured in runbooks, incident logs, and internal wikis — not left to reside in the heads of individual team members.
Key performance indicators for the team should include mean time to detection (MTTD), mean time to resolution (MTTR), percentage of incidents resolved via automated playbooks versus manual intervention, and the frequency of repeat incidents for the same root cause. Tracking these metrics over time reveals where the team is most effective and where investment in tooling or process improvement will have the greatest impact.
High-Frequency Monitoring: The Early Warning System
1. Why Reactive Monitoring Falls Short
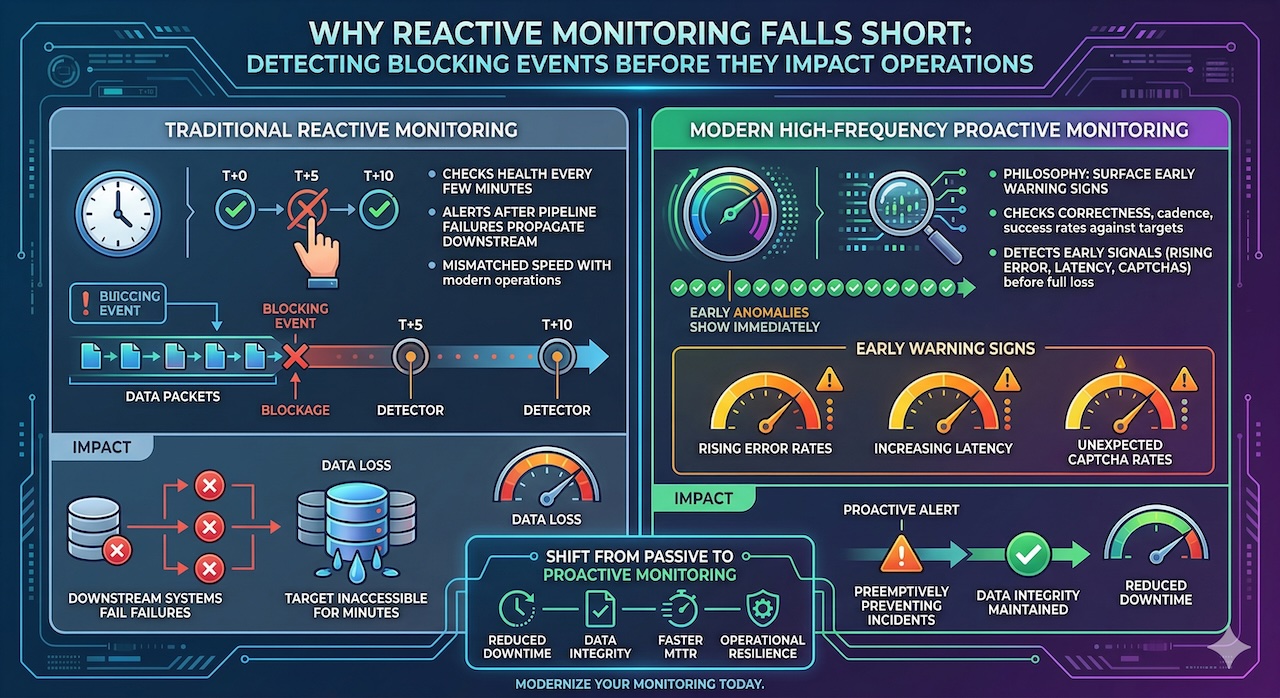
Traditional monitoring approaches such as checking system health every few minutes, alerting on pipeline failures after they have propagated downstream are fundamentally mismatched with the speed at which blocking events can impact operations. By the time a monitoring system tuned for five-minute intervals detects a blocking event, the affected target may have been inaccessible for several minutes, resulting in significant data loss or downstream failures.
High-frequency monitoring operates on a different philosophy: surface anomalies as early as possible, before they become incidents. Rather than checking whether pipelines are running, high-frequency monitoring checks whether they are running correctly, on the right cadence, with the expected success rates, and against the expected targets. The goal is to detect the early warning signs of a blocking event such as rising error rates, increasing latency, unexpected CAPTCHA rates before access is fully lost.
2. What to Monitor
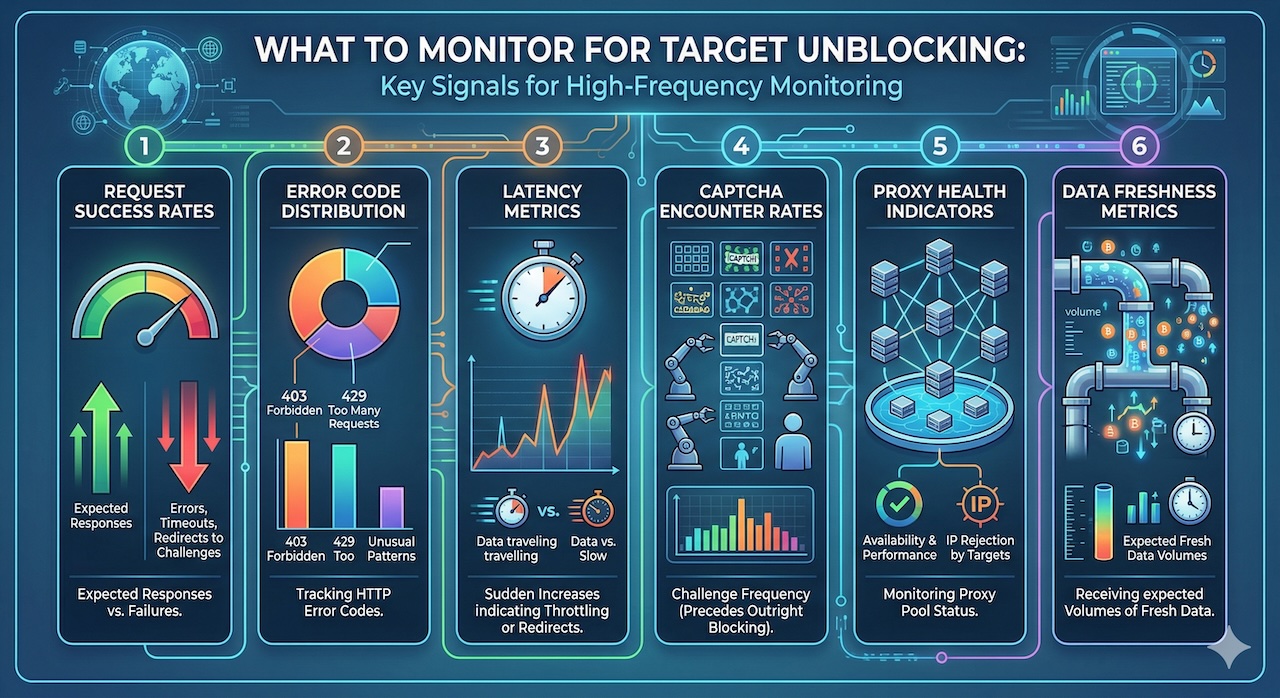
Effective high-frequency monitoring for target unblocking covers several key signal categories:
- Request success rates: The percentage of requests to each target that return expected responses versus errors, timeouts, or redirects to challenge pages.
- Error code distribution: Tracking which HTTP error codes are being returned, with particular attention to 403 Forbidden, 429 Too Many Requests, and unusual 5xx patterns that may indicate blocking or throttling.
- Latency metrics: Sudden increases in response latency can be an early indicator of throttling or redirects to challenge pages before the error codes change.
- CAPTCHA encounter rates: The frequency with which requests are challenged with CAPTCHAs, which typically precedes outright blocking.
- Proxy health indicators: The availability and performance of proxy pools, including the rate at which specific IPs are being rejected by targets.
- Data freshness metrics: Downstream indicators of whether data pipelines are receiving expected volumes of fresh data from each target.
3. Setting the Right Monitoring Cadence
The appropriate monitoring frequency depends on the criticality of the target and the sensitivity of the downstream systems that depend on it. For high-priority targets, monitoring should operate at or near real time, with sub-minute check intervals and immediate alerting on anomalies. For lower-priority targets, less frequent checks may be acceptable.
Crucially, the monitoring cadence must be calibrated against both the cost of false negatives (missed blocking events) and the cost of false positives (alert fatigue). A monitoring system that fires alerts constantly trains teams to ignore them, which defeats the purpose entirely. Investing in anomaly detection and adaptive thresholds rather than static alert rules is essential for maintaining a signal-to-noise ratio that keeps the team engaged and responsive.
4. Infrastructure and Tooling
High-frequency monitoring at scale requires investment in appropriate infrastructure. This typically includes real-time streaming data pipelines that aggregate monitoring signals from distributed collection agents, time-series databases optimized for high-ingestion-rate metric data, alerting systems that support sophisticated routing and escalation logic, and dashboards that give both the unblocking team and leadership visibility into the health of access across the full portfolio of targets.
For organizations at sufficient scale, machine learning-based anomaly detection can significantly improve the effectiveness of monitoring by identifying subtle patterns that static threshold-based alerting would miss. Behavioral baselines for each target — capturing normal patterns of request success rates, latency, and error distributions — enable the system to flag deviations that may not exceed any absolute threshold but are statistically unusual.
How the Team and Monitoring Work Together
A dedicated unblocking team and a high-frequency monitoring system are most powerful when they operate as an integrated system with a continuous feedback loop. Monitoring surfaces anomalies and potential blocking events; the team investigates and resolves them; the resolution informs updates to both the monitoring rules and the response playbooks.
Escalation protocols define clearly when automated systems should hand off to human responders. Not every anomaly requires human intervention — many common blocking scenarios can be resolved entirely through automated responses such as IP rotation, header cycling, or retry logic with modified request parameters. The monitoring system should be able to trigger these automated responses directly, escalating to the human team only when automated responses are ineffective or when the scope and severity of the incident exceeds predefined thresholds.
For large-scale blocking events where a significant portion of targets are affected simultaneously, or where a critical high-priority target becomes fully inaccessible, the team should have a war room protocol that brings together the relevant stakeholders, establishes a clear incident commander, and maintains a running log of actions taken and their outcomes. Speed and coordination are the priorities in these scenarios; bureaucracy and ambiguity are the enemies.
Post-mortems following significant blocking events are an essential mechanism for continuous improvement. Every incident should be documented with a timeline, a root cause analysis, a record of the interventions that were attempted and their outcomes, and specific recommendations for preventing recurrence. Over time, this body of knowledge becomes one of the organization's most valuable operational assets.
Scaling the System as Operations Grow
As the number of targets, geographies, and use cases grows, both the unblocking team and the monitoring infrastructure must scale with them. The key to sustainable scaling is progressive automation — shifting as much of the response burden as possible from human responders to automated systems, so that the human team can focus on the novel, complex incidents that automation cannot handle.
Tier-1 automated responses should handle the most common and well-understood blocking scenarios without human involvement. These include automatic IP rotation when a specific IP is blocked by a target, header and user-agent cycling when behavioral detection is triggered, adaptive rate limiting to reduce request velocity when throttling is detected, and automatic failover to backup proxy pools when primary pools are degraded.
As the volume and diversity of targets increases, distributed monitoring becomes essential. A single centralized monitoring system becomes a bottleneck and a single point of failure. Architecturally, monitoring agents should be deployed close to the collection infrastructure, with aggregation happening progressively rather than all at once. Geographic distribution of monitoring ensures that regional blocking events are detected by monitoring agents in the same region, reducing the risk that network topology masks the true nature of the issue.
Investment in machine learning-based anomaly detection becomes increasingly valuable as the portfolio of targets grows. Static alert rules that work well for ten targets become unmanageable for a thousand — each target has its own behavioral baseline, and maintaining individual thresholds for each is impractical. ML-based approaches can learn these baselines automatically and adapt as target behavior changes over time.
Best Practices and Lessons Learned
Organizations that have built effective, scalable unblocking infrastructure share several common lessons:
- Start with visibility: You cannot fix what you cannot see. Investing in monitoring and observability before building out automation and response playbooks is almost always the right sequence. Without accurate, timely data about what is happening across your target portfolio, all other efforts are operating in the dark.
- Standardize your playbooks before you scale your team: A team of five following well-documented, tested playbooks will outperform a team of twenty improvising responses on the fly. Playbook development is an investment that pays compounding returns as the team grows.
- Measure mean time to resolution relentlessly: MTTR is the single most important metric for an unblocking team. Every improvement in tooling, automation, and process should be evaluated against its impact on MTTR. Teams that do not track this metric cannot demonstrate the value of their work or identify where to focus improvement efforts.
- Invest in cross-functional relationships: The unblocking team does not operate in isolation. Effective access maintenance requires close collaboration with the infrastructure teams that manage proxy pools and IP resources, the engineering teams that own the collection applications, and the product or client-facing teams that translate access disruptions into business impact. Building these relationships proactively — rather than under the pressure of an active incident — makes a significant difference in response effectiveness.
- Treat every incident as a learning opportunity: The organizations that maintain the best access reliability are not those that never experience blocking events — they are those that learn most efficiently from every event they experience. A culture of blameless post-mortems and systematic knowledge capture is essential to continuous improvement.
Conclusion
Maintaining reliable access to target sources at scale is one of the defining operational challenges for organizations that depend on external data. The combination of a dedicated unblocking team and a high-frequency monitoring system represents the most effective structural response to this challenge — not because it eliminates blocking events, but because it minimizes their duration and impact while building organizational capacity to respond ever more efficiently over time.
The competitive advantage created by this infrastructure is real and significant. Organizations that can maintain consistent, high-quality access to their targets while competitors struggle with blocking-related data gaps and pipeline failures are positioned to deliver better products, more reliable services, and stronger SLA performance. In data-intensive industries, access reliability is not just an operational concern — it is a strategic differentiator.
For organizations that have not yet made this investment, the first step is straightforward: audit your current unblocking posture. How quickly do you detect blocking events today? How long does it take to resolve them? How much data loss occurs during that window? What institutional knowledge about your targets exists, and where is it documented? The answers to these questions will reveal the gap between your current state and the resilient, scalable access infrastructure described in this article — and will make clear where to start building.
Featured Image generated by ChatGPT and Infographics generated by Google Gemini.
.Share this post
Leave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment