Redirects are one of the simplest concepts in HTTP. A request comes in, the server responds with a 3xx status code and a Location header, and the client follows it.
In isolation, this works exactly as expected.
At scale, it rarely does.
As websites grow and infrastructure becomes more distributed, redirect logic spreads across multiple layers: application code, reverse proxies, CDNs, load balancers and even third-party services. What starts as a simple mapping from one URL to another becomes a system-level concern.
Most redirect issues are not caused by a misunderstanding of HTTP. They are caused by a lack of visibility and coordination across layers.
Redirect logic does not live in one place
In a typical modern stack, redirects can exist in multiple locations at once:
- Application-level routing (e.g., framework redirects)
- Web server configuration (Nginx, Apache)
- CDN or edge rules (Cloudflare, Fastly)
- Platform or CMS plugins
- External redirect management tools
Each layer can independently intercept a request and issue a redirect.
The problem is that these layers do not share state.
That means a request like:
http://example.com/page
might be processed like this:
- CDN forces HTTPS:
https://example.com/page - App-level rule rewrites path:
/resources/page - Legacy server rule redirects:
/learn/page
Result:
http → https → /resources → /learn
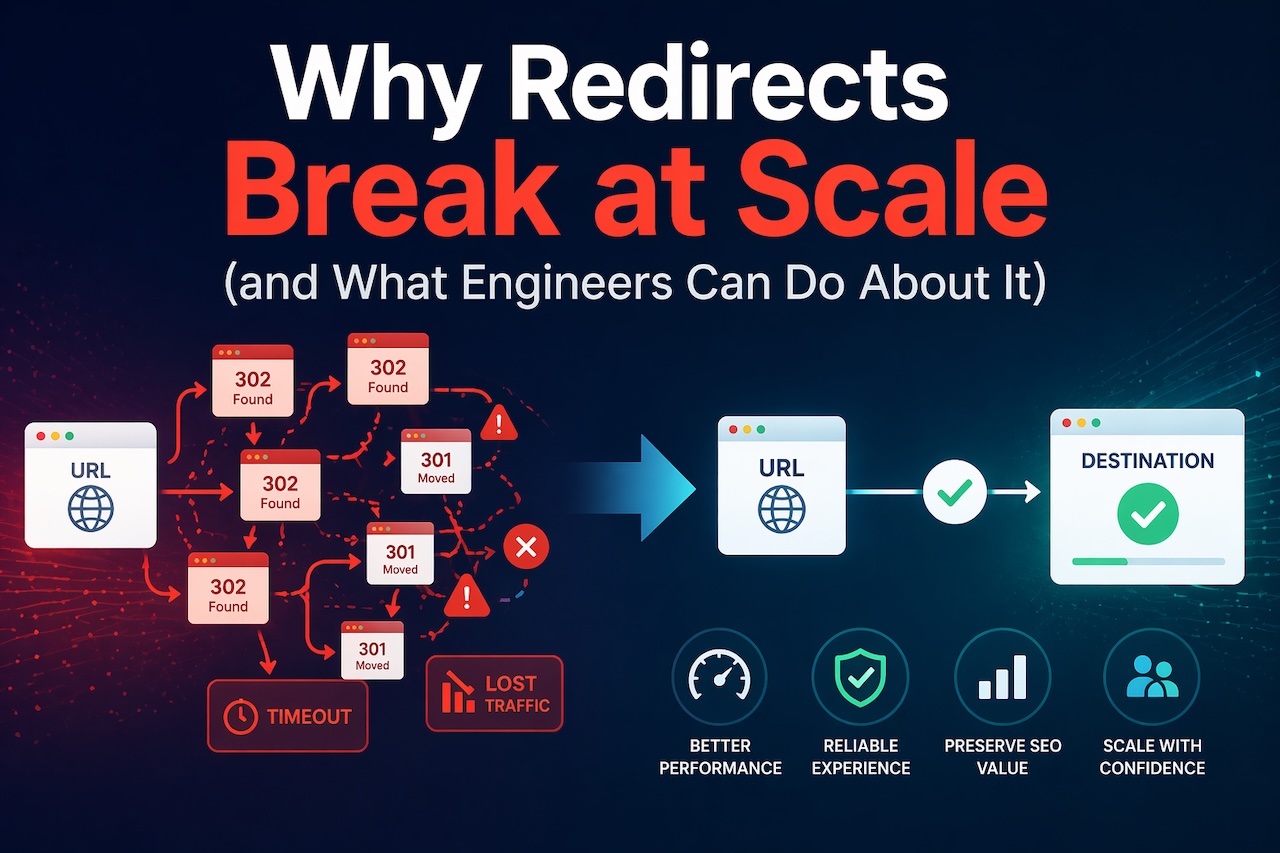
From a single request, you now have a multi-hop redirect chain created across three different systems.
No single system “owns” the full behavior.
Redirect chains are a systems problem
Redirect chains are often treated as an SEO issue, but at a technical level, they are a latency and coordination problem.
Each hop introduces:
- An additional round-trip (TCP + TLS where applicable)
- Increased time to first byte (TTFB)
- More work for clients and crawlers
For users on mobile networks or high-latency connections, this can be noticeable.
For crawlers, chains introduce another issue: crawl budget efficiency. Even if a crawler follows the chain, long or slow chains increase the likelihood of incomplete traversal.
More importantly, chains are rarely intentional. They are a side effect of:
- Incremental migrations
- Layered infrastructure changes
- Teams working in isolation
Without a way to audit redirect behavior globally, they accumulate silently.
Redirect loops are usually configuration conflicts
Loops are more severe and typically result from conflicting rules across layers.
A classic example:
CDN rule: force HTTP → HTTPS
Server rule: force HTTPS → HTTP (misconfigured or legacy)
Result:
http → https → http → https → ...
Another common pattern:
Non-www → www at one layer
www → non-www at another
Because each system assumes it is authoritative, they create a feedback loop.
From an engineering perspective, loops are not “bugs” in one place. They are emergent behavior from multiple valid rules interacting incorrectly.
Method handling is often overlooked
Most redirect discussions focus on URLs, but HTTP methods matter, especially in API-heavy systems.
If a redirect changes the request method (e.g., POST → GET), you can break:
- Form submissions
- API endpoints
- Authentication flows
This is why status codes like 307 and 308 exist—to preserve the original method.
While this is less relevant for crawlers (which mostly issue GET requests), it becomes critical in:
- Microservices architectures
- API gateways
- Stateful workflows
At scale, redirect handling is not just about where traffic goes, but how requests are replayed.
Why debugging redirects is harder than it should be
One of the main challenges with redirects is that they are distributed and opaque.
When debugging, engineers often rely on:
- Browser DevTools (single request view)
- curl or CLI tools
- Logs from individual layers
Each of these shows only part of the picture.
What is missing is:
- A full redirect chain across all layers
- A consistent view of status codes and destinations
- The ability to audit behavior across many URLs at once
This is where most teams struggle. Not with creating redirects, but with understanding how they behave in aggregate.
The three types of tools engineers actually need
In practice, redirect management breaks into three distinct capabilities:
1. Crawling (system-wide visibility)
Crawlers simulate how a client or bot traverses a site, following redirects and reporting:
- Chains
- Loops
- Final destinations
- Status codes
This is essential for:
- Migrations
- Audits
- Debugging distributed behavior
2. Testing (request-level inspection)
Testing tools focus on individual URLs, providing:
- Full redirect paths
- Headers and response details
- Timing information
Useful for:
- Verifying fixes
- Debugging specific endpoints
- Inspecting edge cases
3. Management (control layer)
Management tools handle:
- Creating redirects
- Updating rules
- Applying logic at scale
They provide:
- Bulk operations
- Pattern-based rules
- Centralized control
Most teams have at least one of these. Very few have all three working together.
Designing redirect systems that do not break
To avoid common failure modes, redirect handling needs to be treated as a first-class system concern, not an afterthought.
A few practical principles:
1. Minimize layers of responsibility
Define where redirects should live. Avoid overlapping logic between CDN, server and application unless necessary.
2. Prefer direct mappings
Always point source URLs directly to their final destination. Do not rely on intermediate redirects.
3. Audit before adding new rules
Before introducing new redirects, check existing behavior. Many chains are created by layering new rules on top of old ones.
4. Monitor continuously
Redirect issues often emerge over time. Monitoring helps catch:
- New chains
- Unexpected status changes
- Latency increases
5. Treat redirects as infrastructure
They sit in the request path. If they fail, your site fails. Reliability and observability matter.
Where this becomes critical
Redirect complexity increases significantly in scenarios like:
- Domain migrations
- Multi-region deployments
- CDN edge logic
- Large content restructures
- API versioning
In these cases, redirect behavior directly affects:
- Performance
- Availability
- SEO
- User experience
And most importantly, it becomes harder to reason about without the right tooling.
Final thought
Redirects are simple at the protocol level but complex in real systems.
The more distributed your infrastructure becomes, the more likely it is that redirect behavior will fragment across layers. When that happens, problems are not caused by a single misconfiguration, but by how multiple systems interact.
If you want a deeper breakdown of how redirect crawlers, testing tools and management systems fit together—and how to choose the right approach—you can read the full guide on URL redirection tools from urllo.
Featured Image generated by ChatGPT.
Share this post
Author

Read the latest articles from Reza Ali
S&P 500 Forecast: Market Outlook and Key Trends for 2026

April 12, 2026
The S&P 500 forecast for 2026 points to a year of moderate growth mixed with potential risks. Current projections from market analysts suggest the index could rise steadily over the course of the year, with average expectations hovering around a mid-single-digit percentage gain.
Learn moreTop 10 Dedicated Server Providers in 2026
January 12, 2026
Dedicated infrastructure in 2026 is no longer reserved only for large enterprises. Growth in AI workloads, high-throughput SaaS, and data-intensive platforms has pushed businesses toward predictable performance and isolation. Managed dedicated servers< [...]
Learn moreLeave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment