
Organizations invest heavily in acquiring large volumes of data to power analytics, automation, and decision-making. However, one of the most overlooked factors in controlling these costs is not the price of tools or infrastructure, but the efficiency of the data acquisition process itself. Specifically, the success rate of data retrieval plays a critical role in determining how much organizations ultimately spend. While many focus on reducing per-request or bandwidth costs, the real opportunity for savings lies in improving how often those requests actually succeed.
What Is Data Acquisition Success Rate?
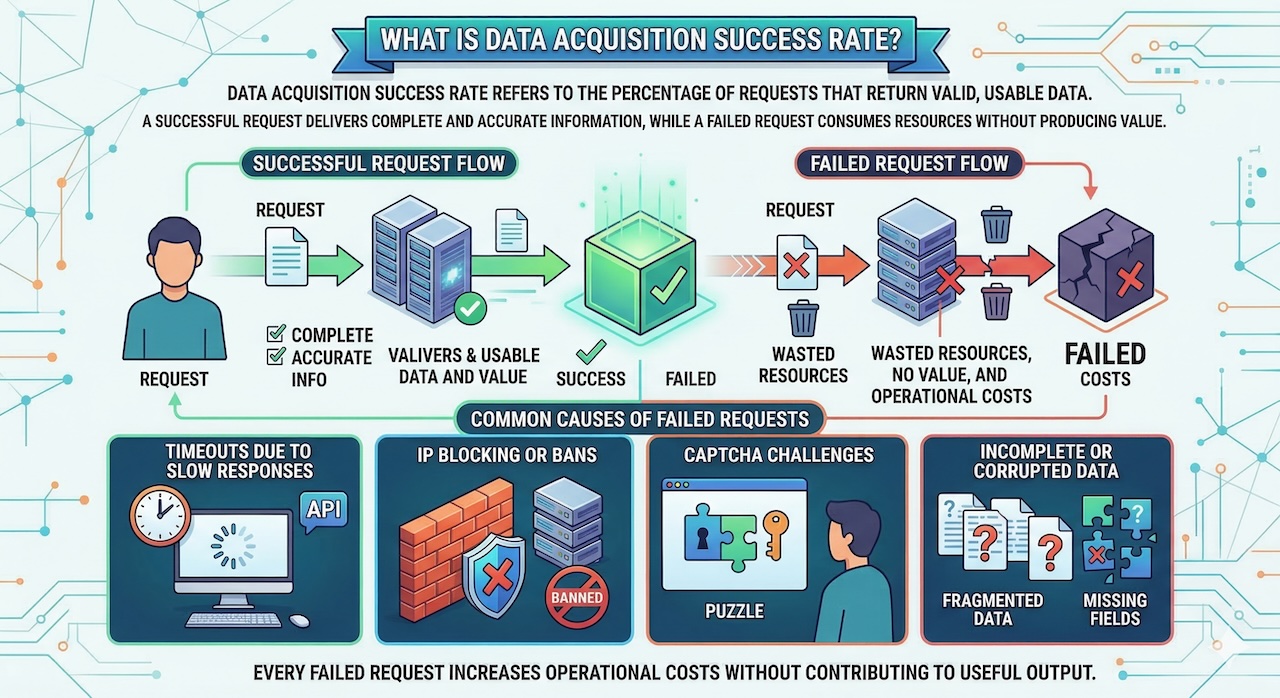
Data acquisition success rate refers to the percentage of requests that return valid, usable data. A successful request delivers complete and accurate information, while a failed request may result in timeouts, blocked access, CAPTCHA challenges, or incomplete data. Every failed request wastes resources, consuming bandwidth, processing power, and time without producing value. When scaled across thousands or millions of requests, even a modest failure rate can significantly inflate operational costs. High-performance proxy providers such as Decodo help improve success rates by offering large IP pools, intelligent routing, and stable connections, enabling more requests to succeed and reducing inefficiencies in data acquisition pipelines.
Why Low Success Rates Are Expensive
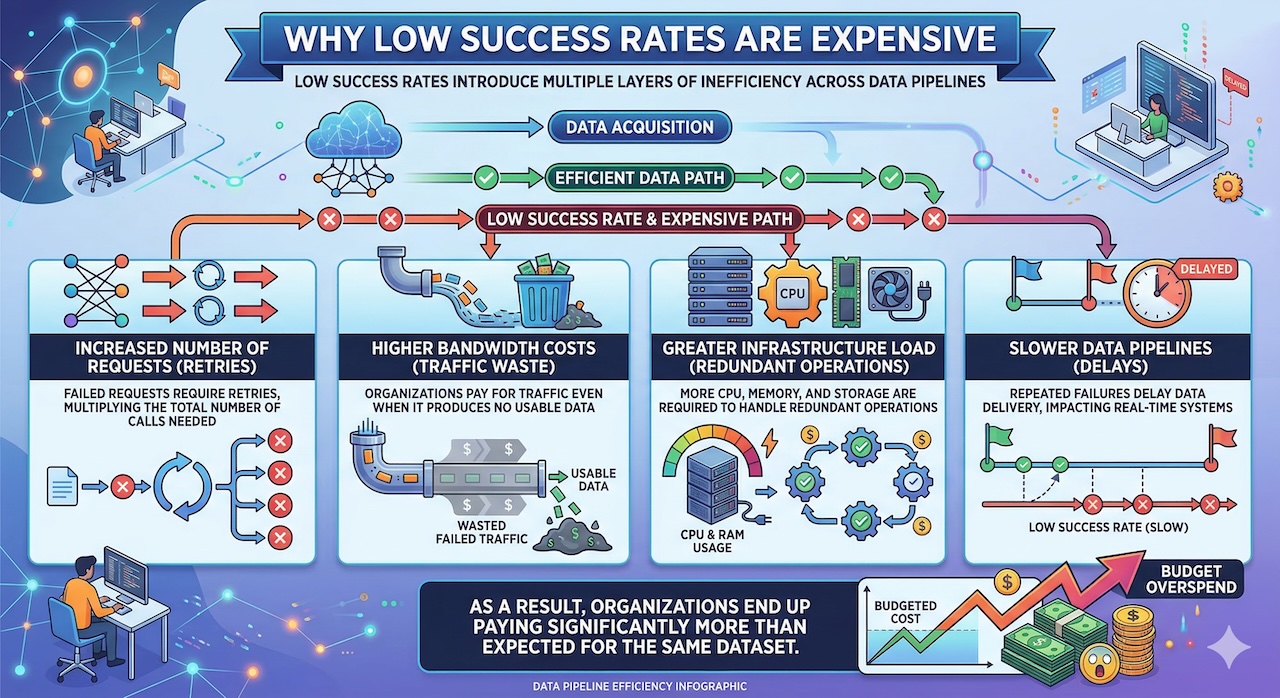
Low success rates introduce multiple layers of inefficiency. First, failed requests typically trigger retries, which increase the total number of requests required to collect the same amount of data. This directly impacts bandwidth usage and proxy consumption. Second, additional retries place a heavier load on infrastructure, requiring more CPU, memory, and storage resources to process redundant operations. Third, delays caused by repeated failures slow down data pipelines, which can be particularly problematic for systems that rely on real-time or near-real-time insights. In effect, organizations are not just paying for data—they are paying for inefficiency.
Understanding the Cost Equation
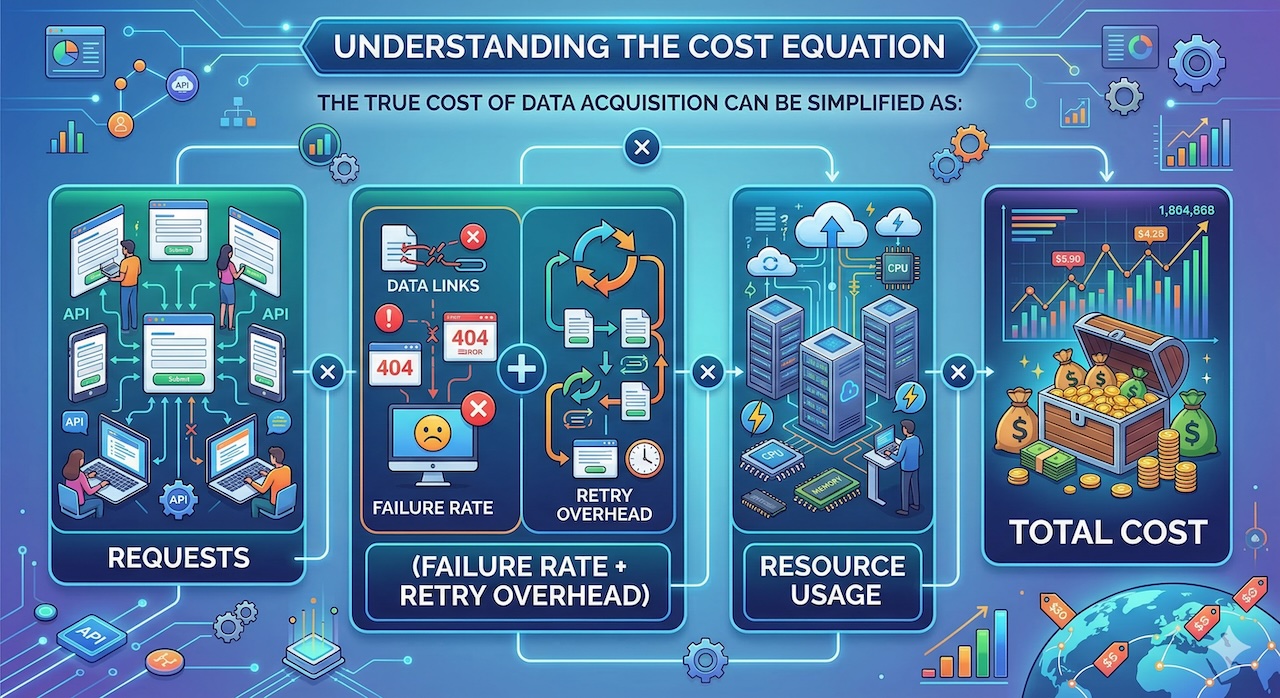
The cost implications become clearer when viewed through a simple equation: total data acquisition cost is driven by the number of requests multiplied by the failure rate and the overhead associated with retries and resource usage. For example, a system with a 70 percent success rate effectively wastes 30 percent of its resources on failed attempts. In contrast, improving that success rate to 95 percent dramatically reduces waste and lowers the number of total requests required. Even incremental improvements in success rate can lead to disproportionately large cost savings.
How High Success Rates Reduce Costs
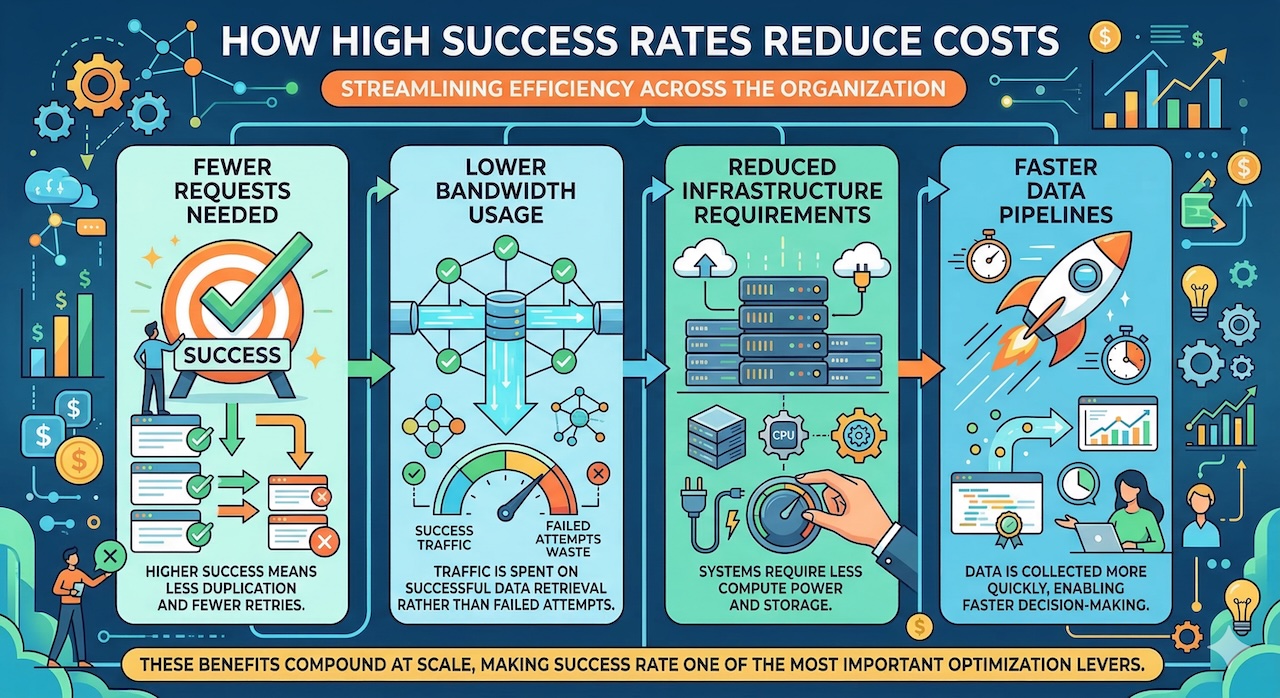
High success rates reduce costs in several ways. Fewer failed requests mean fewer retries, which directly lowers the total number of requests needed. This leads to reduced bandwidth consumption, as organizations are no longer paying for traffic that produces no usable output. Additionally, with fewer redundant operations, infrastructure demands decrease, allowing systems to run more efficiently and at lower cost. Faster, more reliable data retrieval also shortens processing times, enabling quicker insights and more responsive decision-making.
Key Drivers of High Success Rates
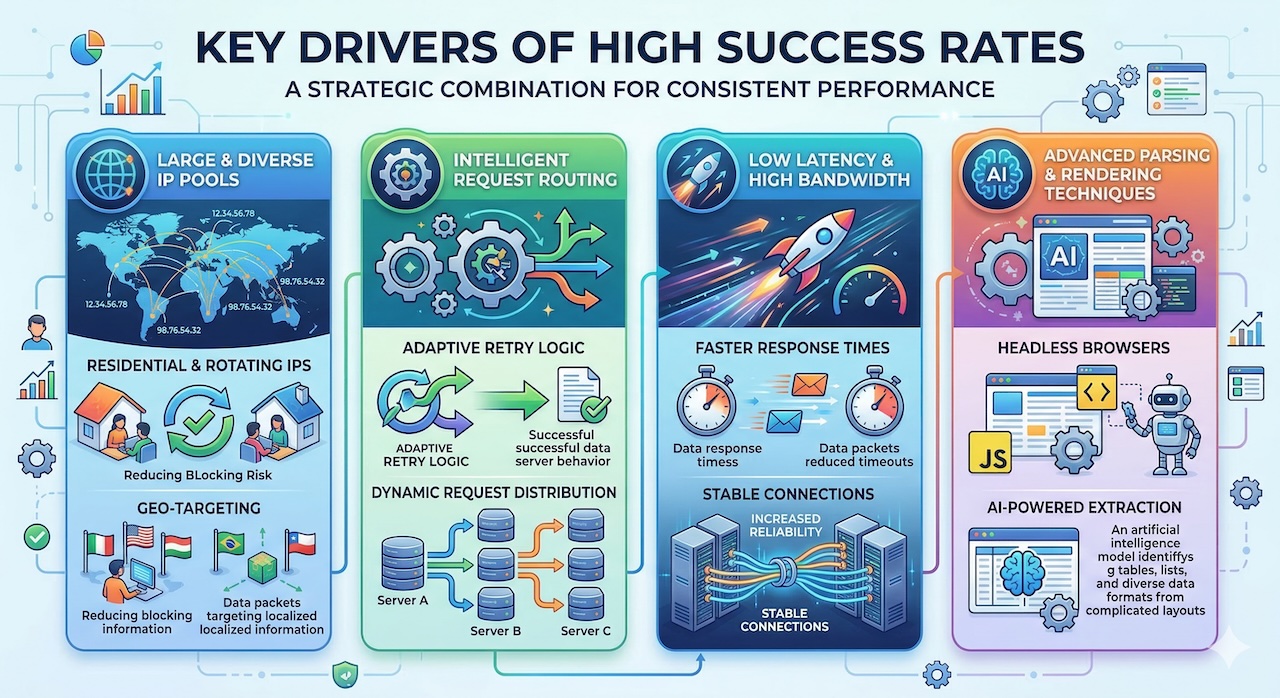
Achieving high success rates depends on several key factors. One of the most important is access to a large and diverse IP pool. By distributing requests across a wide range of IP addresses—particularly residential IPs—systems can avoid detection and blocking, which are common causes of failed requests. Intelligent request routing and retry strategies further improve outcomes by adapting to network conditions and dynamically selecting the most effective paths. Low latency and high bandwidth infrastructure also play a role, as faster response times reduce the likelihood of timeouts. Additionally, advanced parsing techniques, including the use of headless browsers and AI-powered extraction tools, help ensure that data is correctly captured even from dynamic or complex web environments.
The Role of Proxy Infrastructure
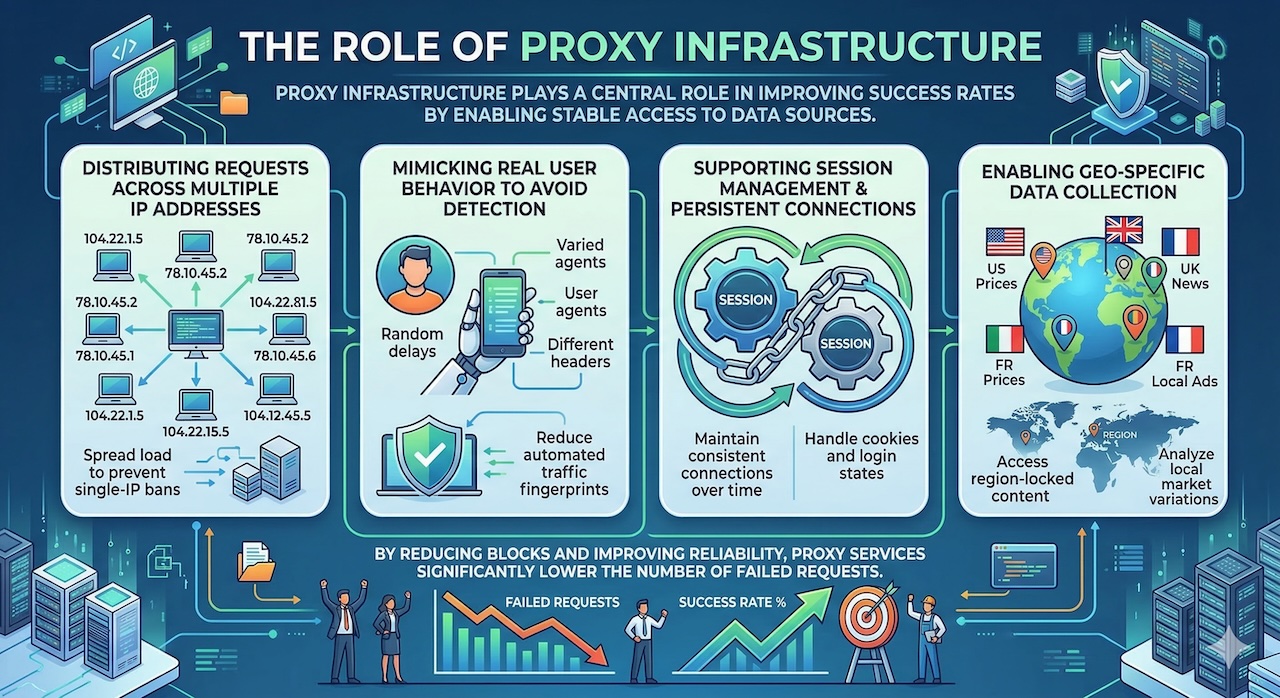
Proxy infrastructure is especially critical in this context. High-quality proxy networks enable stable and consistent access to data sources by masking request origins and distributing traffic in a way that mimics real user behavior. Features such as IP rotation, session management, and geo-targeting allow systems to access region-specific content while minimizing the risk of detection. By improving access reliability, proxy services significantly increase success rates and, in turn, reduce the overall cost of data acquisition.
Real-World Applications
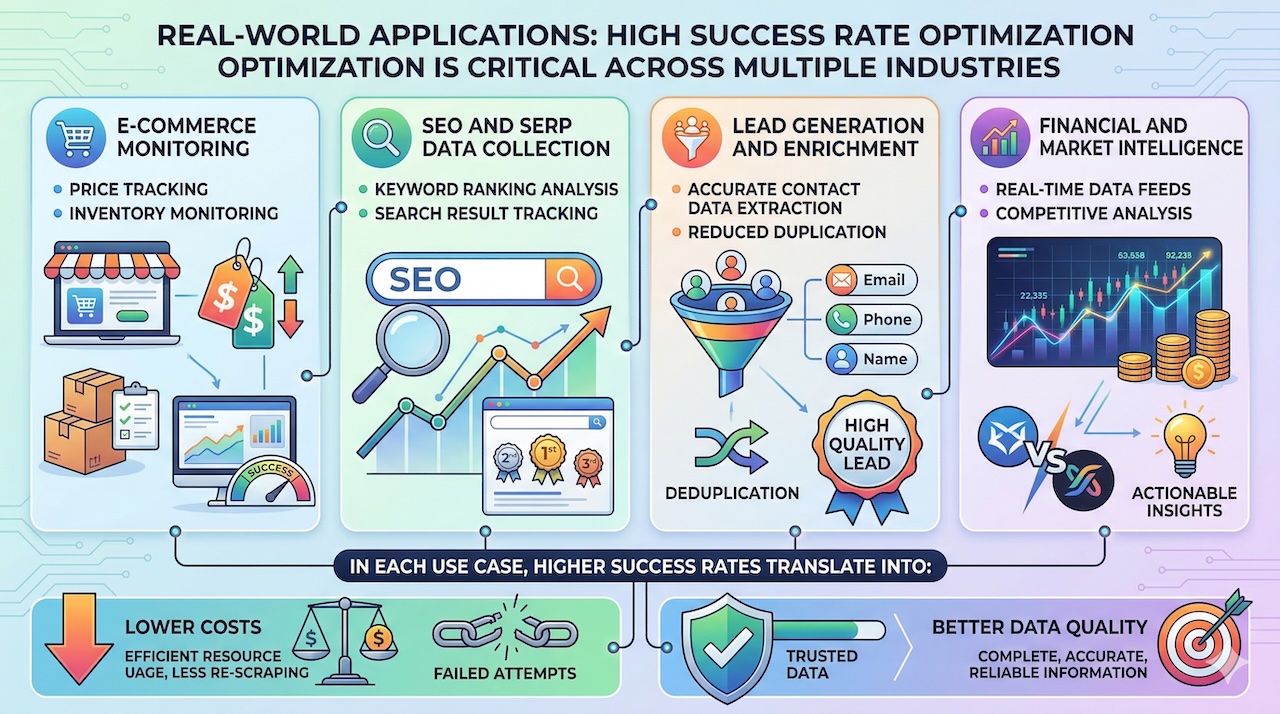
These principles apply across a wide range of real-world use cases. In e-commerce, companies rely on data acquisition to monitor competitor pricing and inventory levels. In SEO, businesses track search engine results to inform optimization strategies. Lead generation and data enrichment workflows depend on accurate and complete contact data, while financial and market intelligence systems require timely and reliable information. In each case, higher success rates translate directly into lower costs and better outcomes.
Best Practices to Improve Success Rate
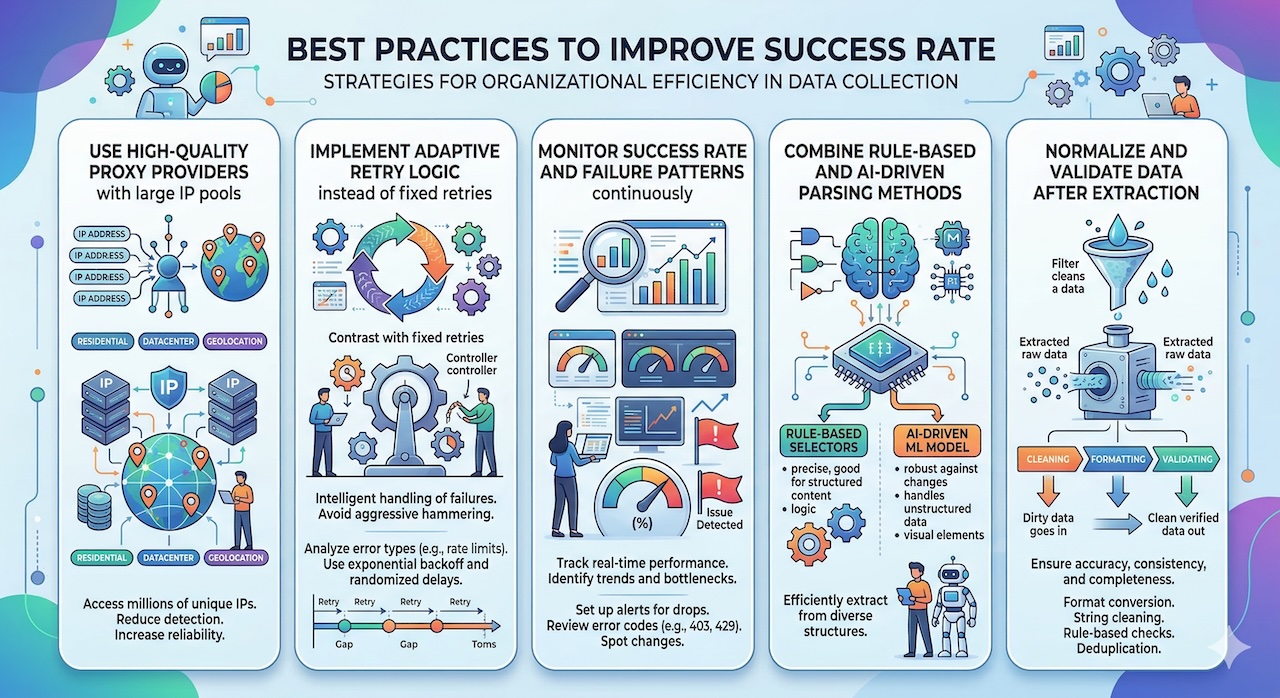
To maximize return on investment, organizations should adopt best practices focused on improving success rates. This includes selecting high-quality proxy providers, implementing adaptive retry logic, and continuously monitoring key performance metrics. Combining multiple extraction techniques—such as rule-based parsing and AI-driven methods—can further enhance reliability. Equally important is the normalization and validation of data after extraction, ensuring that the final output is consistent and usable.
Metrics That Matter

Ultimately, cost optimization in data acquisition is not about finding the cheapest solution, but about building the most efficient one. Metrics such as success rate, cost per successful request, retry rate, and latency provide a more accurate picture of performance than raw pricing alone. Organizations that prioritize these metrics are better positioned to reduce waste, improve system performance, and generate higher-quality data.
Conclusion
High success rates are a powerful lever for reducing costs in data acquisition. By minimizing failures, reducing retries, and improving overall efficiency, organizations can significantly lower their operational expenses while enhancing the reliability of their data pipelines. Rather than focusing solely on price, businesses should prioritize performance and success rate as the true drivers of cost efficiency.
Featured Image generated by ChatGPT and Infographics generated by Google Gemini.
Share this post
Leave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment