
For any growing .NET application, background processing isn't just a feature; it's the backbone of a scalable and responsive system. Whether it's processing payments, sending notifications, or running complex reports, the ability to execute tasks asynchronously is critical. The default tool for this in the .NET ecosystem is the IHostedService.
It starts as a simple, elegant solution for polling tasks. But as an application succeeds and its architecture scales to multiple instances, this simple worker can quietly become a ticking time bomb, introducing risks to stability, performance, and even your deployment pipeline.
In this article, we'll explore the hidden technical debt of IHostedService at scale, drawing from our real-world experience building a mission-critical FinTech onboarding workflow. We’ll outline a strategic playbook for recognizing when a polling worker has reached its limit and for gracefully evolving your system to a robust, distributed background job framework like Hangfire.
The Architectural Crossroads: A Real-World FinTech Scenario
While delivering .NET software development services for a financial technology client, our team was tasked with building a modern merchant onboarding platform. A core requirement was orchestrating a multi-step workflow involving several third-party APIs for compliance (KYC/KYB), bank account creation, and crypto wallet provisioning. This process was inherently asynchronous and could take several minutes, relying on webhooks and long-running background tasks.
The cryptocurrency payment platform already used a familiar approach for background processing: custom IHostedService implementations that periodically polled the database for pending work. This pattern worked well in development. However, as the system moved closer to production and horizontal scaling became necessary, several critical limitations of this approach began to surface.
The Hidden Dangers
While IHostedService is an excellent tool for simple, single-instance tasks, its limitations become apparent in a distributed, cloud-native environment.
1. The "Thundering Herd" and Race Conditions
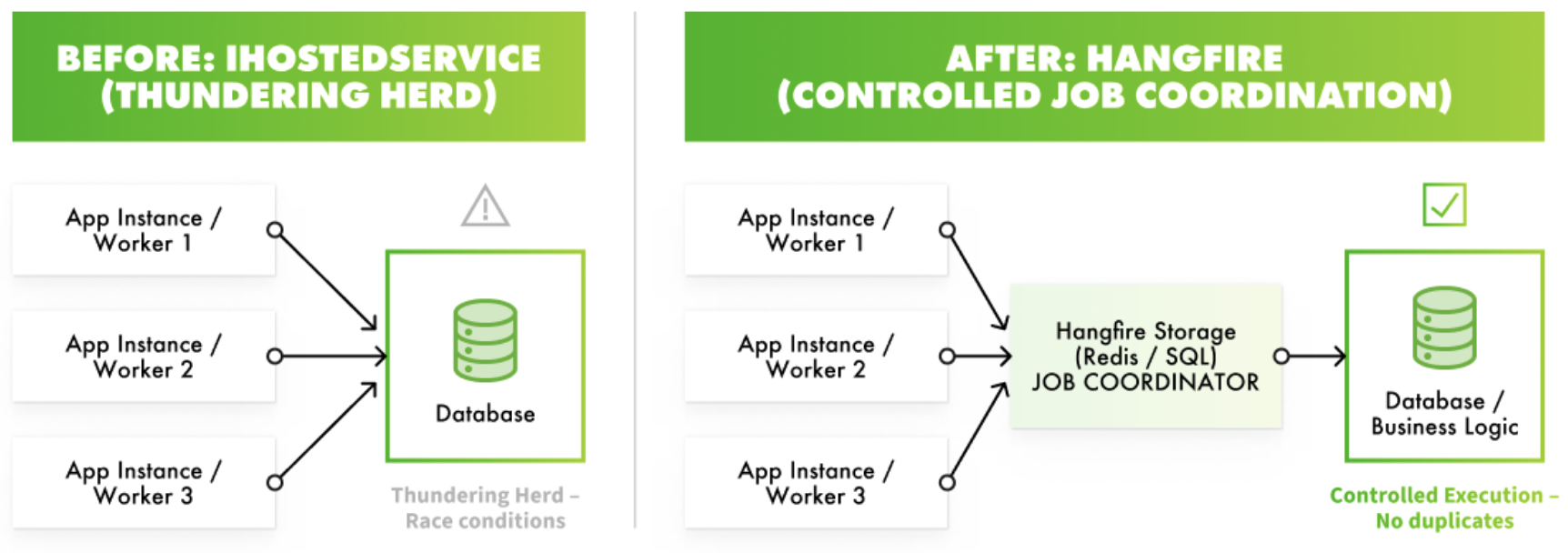
When you deploy your application to more than one server instance for high availability, a standard practice in the cloud, you now have multiple IHostedService workers running in parallel. All of them will wake up at roughly the same time and query the database for the same work.
This "thundering herd" creates immediate race conditions. Without a sophisticated, distributed locking mechanism, multiple workers will attempt to process the same application, leading to duplicate API calls, corrupted data, and wasted resources. While you can implement atomic database operations (like FindAndClaim) to mitigate this, you are now spending development effort solving a distributed computing problem that is already solved in dedicated frameworks.
2. The Observability Black Box
When a background task fails, you need to know three things immediately: What failed? Why did it fail? And is it being retried? With a custom IHostedService, the only answer is to sift through logs. There is no built-in dashboard to view job status, view execution history, or manually re-trigger a failed task. This lack of observability makes troubleshooting a manual, slow, painful process that increases your team's operational burden.
3. Fragile, Manual Retry Logic
What happens if a third-party API is temporarily unavailable? A simple polling worker will try the same failed operation again on its next interval (e.g., 5 seconds later), and again, and again. This can overwhelm a struggling downstream service and fill your logs with spam. Implementing proper exponential backoff with jitter requires writing complex, stateful retry logic from scratch.
4. The Deployment Deadlock
This is one of the most surprising and disruptive issues. A hosted service with a while(true) loop is designed to run forever. However, many CI/CD pipelines rely on short-lived tasks, like running a dotnet run --migrate command to apply database schema changes.
If your primary application is responsible for migrations, starting the application will also begin your long-running worker. The worker never exits, so the migration command never finishes. The deployment pipeline hangs, eventually timing out with a cryptic "runner lost communication" error. This forces you to write complex conditional logic in your application startup to manage your deployment process.
Evolving the Architecture: Choosing a Distributed Job Framework
Upon recognizing these challenges, we knew we needed to evolve. We evaluated two primary alternatives to IHostedService for our FinTech platform development: serverless or an integrated job library.
Serverless (e.g., AWS Lambda with SQS/EventBridge)
Serverless is a powerful, event-driven pattern that offers incredible scalability. The "Acknowledge First, Process Second" pattern, where a webhook immediately enqueues a message to a queue like SQS, which then triggers a Lambda function, is a modern gold standard.
However, it introduces a different kind of complexity within our system where the majority of the business logic, domain models, and service dependencies for the onboarding process reside in a single, comprehensive .NET back-end solution. Porting this complex, interconnected logic into a Lambda function is not a simple "lift and shift." It would have required either:
- Creating a "fat" Lambda with a large deployment package containing many dependencies, which can lead to slower cold starts and goes against the serverless principle of small, focused functions.
- Undertaking a major microservices-style refactoring of the core application, which was far outside the scope of the immediate business requirement.
Integrated Job Library (Hangfire)
Hangfire is a mature, "batteries-included" background job processing library that runs inside your existing ASP.NET Core application. It uses a persistent back end (like Redis, which we used, or SQL Server) to coordinate jobs across all instances of your application.
For this project, Hangfire provided the perfect balance of power and simplicity.
The Solution in Practice: How Hangfire Defused the Time Bomb
Migrating our logic from IHostedService to Hangfire was a strategic move that solved all our scaling problems out of the box.
- Built-in Concurrency Management: Hangfire’s storage backend serves as the single source of truth. It ensures that only one worker across all your server instances executes a specific job at a time. The "thundering herd" and race conditions disappeared without us writing a single line of locking code.
- Rich Observability via Dashboard: Hangfire provides a comprehensive dashboard right out of the box. We could instantly see jobs that were processing, succeeded, failed, and scheduled. We could inspect exceptions from failed jobs and manually re-enqueue them with a single click. This drastically reduced the time it took to diagnose and resolve issues.
- Automatic, Intelligent Retries: By simply adding an attribute (
[AutomaticRetry]) to our job methods, we got robust, exponential backoff retries for free. Hangfire automatically handles temporary failures, and if a job fails permanently, it's moved to a "Failed" state for manual review instead of running forever. - Seamless Deployments: Because Hangfire jobs are scheduled rather than run on application startup, our database migration commands now execute instantly and exit cleanly. The deployment deadlock was resolved entirely.


Final Thoughts
The IHostedService is a valuable part of the .NET ecosystem, but it's essential to recognize its limitations. For applications with critical, multi-step background workflows that need to scale across multiple servers, a dedicated framework like Hangfire is a necessity for building a production-grade system.
By proactively migrating our clients' onboarding workflow, we transformed a potential source of instability into a resilient, observable, and scalable asset. If the challenges of scaling your background tasks sound familiar, it might be time to evaluate your own architecture.
Share this post
Author

Leave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment